
Bom dia a todos,
como estão?
Vamos analisar os dois tópicos a seguir e com isso finalização o primeiro tópico de estudo: Planejar e implementar recursos da plataforma de dados, ele corresponde de 20% a 25% da prova.

Vamos iniciar com as recomendações de Particionamento. Mas porque particionar? Alguns pontos que podemos ter essa necessidade:
- Limitações de espaço de armazenamento
- A capacidade máxima de armazenamento pode ser alcançada em um servidor.
- Limites de recursos de computação. Exceder isso pode resultar em tempo limite (timeout)
- Largura de banda da rede e exceder isso pode resultar em solicitações com falha
Quando se é pensando no escopo do armazenamento precisamos considerar alguns pontos para a projeção das tabelas no Azure:
- As linhas e partições chaves devem ser selecionadas baseado em como o dado é acessado. Com isso fornece-se uma chave de duas partes, que inclui a chave da partição e a chave da linha.
- Baseado nos seus requisito, deve-se considerar index ou diferentes armazenamentos dos dados que suportam indexação.
- Armazenamento de tabelas no Azure suporta operação transacional para tabelas que pertencem a mesma partição.
- Use a mesma chave de partição ou uma única para cada tabela com base na modelagem dos dados que você deseja aumentar ou agrupar
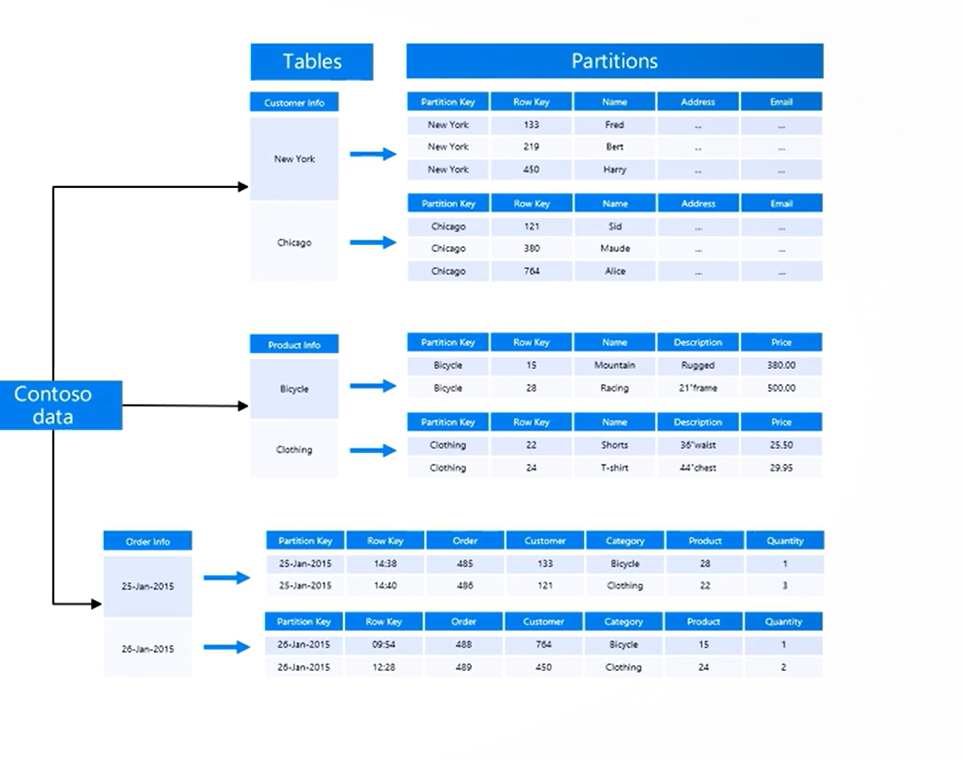
Na imagem acima, podemos validar que a tabela “Customer” está particionado de acordo com cidade, ou seja é a Partition Key (chave de partição), e a Linha chave (row key) é o numero do cliente.
Na tabela “Product” a Partition Key é a categoria e a linha chave é o numero do produto. Dessa forma, os dados são ordenados pela chave linha em CADA partição.
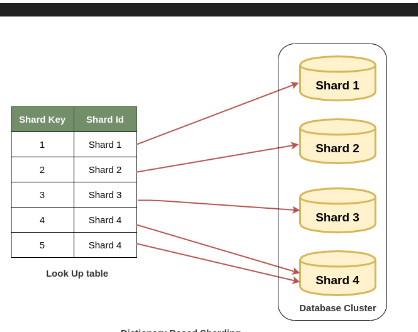
O tópico sobre Recomendação de um banco de dados “sharding”, mostra as opções que podemos fazer para otimizar as tabelas em várias bases ou dividir uma única tabela em várias outras menores. A divisão de uma tabela em vários outras, temos o nome de Horizontal Partition, conforme imagem abaixo.
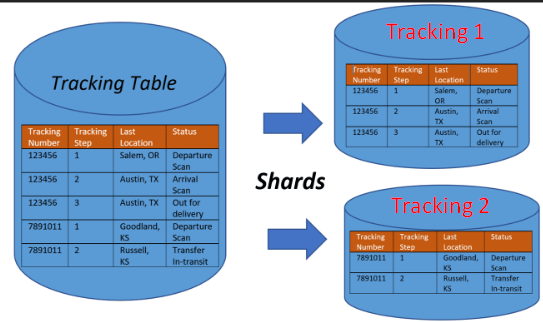
Na imagem abaixo eu divido a minha tabela em vários bancos diferentes para otimização de leitura, disco e recursos do banco de dados como um todo. Essas recomendações são feitas em ambientes muito grande, com Terabytes informações armazenadas, em caso de BI por exemplo.
Então é isso, dúvidas estou a disposição.
