como estão? Estou suuuper sumida né? Mas vim dar um feedback a vocês sobre a DP-300. Finalizar nossa série aqui. Eu não consegui abordar todos os tópicos mas acredito que o que temos aqui já ajuda um cadinho. Fiz a prova mês passado e passei o/ Conseguindo o titulo Azure Database Administrator
Foi fácil? Não. Mas os posts aqui me ajudaram e espero que ajude vocês também. Quero deixar pra vocês a maioria dos tópicos que lembro que caiu viu?
Caiu sobre recuperação de desastres no Azure, Backup TO URL, criação de Credential , saber a diferença entre as ofertas, as opções de banco de dados (Azure SQL, Managed Instance ou VM), diferença ente vcore e DTU, níveis de serviços, migração on premisse pro Azure. Serviços que estão disponíveis em cada oferta. Como automatizar administração no Azure, Templates de Implantação (ARM)
De todos esses tópicos, temos posts aqui. Então bora estudar porque eu acredito ser uma certificação muito importante atualmente na nossa área. Obrigada a todos que estiveram aqui comigo 🙂
Vamos abordar o tópico de configuração e a criação de tarefas automatizadas no mundo da Cloud.
SQL Server em uma VM Azure Com o SQL Server instalado em uma máquina virtual do Azure, você tem acesso aos serviços de agendamento como o SQL Agent ou o Agendador de Tarefas do Windows. Essas ferramentas de automação podem ajudar a manter o quantidade de fragmentação dentro dos índices ao mínimo. Com bancos de dados maiores, um equilíbrio entre um reconstrução e uma reorganização de índices devem ser encontrados para garantir o desempenho ideal. A flexibilidade fornecido pelo SQL Agent ou pelo Agendador de Tarefas (Task Scheduler) permite que você execute tarefas personalizadas. Banco de Dados SQL do Azure Devido à natureza do Banco de Dados SQL do Azure, você não tem acesso ao SQL Server Agent nem ao Windows Task Agendador. Isso significa que a manutenção do índice deve ser controlada de fora do banco de dados. Lá há três maneiras de fazer isso: ● Runbooks de Automação do Azure ● Trabalho do SQL Agent do SQL Server em uma VM do Azure ● Trabalhos elásticos do Azure SQL
Azure SQL Managed Instance Assim como no SQL Server em uma VM do Azure, podemos agendar trabalhos em uma Instância Gerenciada do SQL do Azure por meio do Agent do SQL Server. Isso fornecerá flexibilidade para executar o código projetado especificamente para reduzir a fragmentação nos índices do banco de dados.
Banco de Dados SQL do Azure Devido à natureza do Banco de Dados SQL do Azure, não temos acesso ao SQL Server Agent nem ao Windows Task Agendador. Isso significa que a manutenção do índice deve ser controlada de fora do banco de dados. Tendo duas maneiras de fazer isso: ● Runbooks de Automação do Azure ● Trabalhos elásticos do Azure SQL
Notificações de status da tarefa Uma parte importante da automação é fornecer notificações em caso de falha no trabalho ou se determinado sistema erros são encontrados. O SQL Server Agent fornece essa funcionalidade por meio de um grupo de objetos. Alerta é mais comumente feito por e-mail usando a funcionalidade Database Mail do SQL Server. O outro agente objetos que são usados neste fluxo de trabalho são: ● Operadores—alias para pessoas ou grupos que recebem notificações ● Notificações — notificam um operador sobre a conclusão, sucesso ou falha de um trabalho. ● Alertas—são atribuídos a um operador, para uma notificação ou uma condição de erro definida
Operadores (Operator) Os operadores atuam como um alias para um usuário ou grupo de usuários que foram configurados para receber notificações de conclusão do trabalho ou para ser informado sobre alertas enviados para o log de erros. Um operador é definido como um nome do operador e informações de contato. Normalmente, um operador irá mapear para um grupo de pessoas usando um grupo de e-mail. Ter várias pessoas no grupo de e-mail fornece redundância para que uma notificação não seja perdida se alguém não estiver disponível. Os grupos também são benéficos se um funcionário deixar a organização; o uma única pessoa pode ser removida do grupo de e-mail e você não precisa atualizar todas as suas instâncias. Para enviar e-mail para um operador, você precisa habilitar o perfil de e-mail do SQL Server Agent.
Notificações A notificação de conclusão faz parte de cada trabalho do SQL Server Agent. Você tem a opção de enviar um notificação na conclusão, falha ou sucesso do trabalho. A maioria dos DBAs notifica apenas em caso de falha, para evitar um influxo de notificações para trabalhos bem-sucedidos. As notificações dependem de um operador existente para enviar uma notificação. Essa configuração é feita conforme abaixo:
Alertas Os alertas do SQL Server Agent permitem que você seja proativo com o monitoramento do seu SQL Server. O agente lê o log de erros do SQL Server e quando encontra um número de erro para o qual foi definido um alerta, notifica um operador. Além de monitorar o log de erros do SQL Server, você pode configurar alertas para monitorar o SQL Condições de desempenho do servidor, bem como eventos de Windows Management Instrumentation (WMI). Você pode especifique um alerta a ser gerado em resposta a um ou mais eventos. Um padrão comum é emitir um alerta em todos os erros do SQL Server de nível 16 e superior e, em seguida, adicione alertas para tipos de eventos específicos relacionados a problemas críticos erros de armazenamento ou failover do Grupo de Disponibilidade. Outro exemplo seria alertar sobre condições de desempenho, como alta utilização da CPU ou baixa expectativa de vida útil da página. No próximo artigo iremos aprender como criar os alertas nos ambientes.
Vamos continuar os estudando, agora avaliando o tópico abaixo:
Baselines and Performance Monitoring Uma parte importante do trabalho de um administrador de banco de dados é o monitoramento adequado do desempenho. Esta tarefa não mudar ao mudar para uma plataforma de nuvem. Embora o Azure ofereça ferramentas para monitoramento, pode faltar algumas controles específicos sobre hardware que você teria em um ambiente local que torna entender como identificar e resolver gargalos de desempenho no Azure SQL muito mais crítico.
O que é uma linha de base (baseline)? Uma linha de base é uma coleção de medições de dados que ajudam você a entender o “estado estacionário” normal de o desempenho de seu aplicativo ou servidor. Ter os dados coletados ao longo do tempo permite que você identifique muda do estado normal. As linhas de base podem ser tão simples quanto um gráfico de utilização da CPU ao longo do tempo ou complexas agregações de métricas para oferecer dados de desempenho de nível granular de chamadas de aplicativos específicos. O a granularidade de sua linha de base dependerá da criticidade do desempenho de seu banco de dados e aplicativo. Ferramentas de monitoramento de desempenho. O Azure fornece vários métodos para monitorar o desempenho de seus recursos e criar uma linha de base. Cada método pode ser adaptado para uma métrica específica. Nesta seção, examinaremos as ferramentas de monitoramento do Azure. As métricas que você pode monitorar variam dependendo do tipo de recurso do Azure que você está monitorando, Por exemplo, dependendo do SQL do Azure e do SQL Server em uma VM do Azure, haverá métricas diferentes disponível no portal do Azure.
Perfmon com máquina virtual SQL do Azure Esteja você usando um servidor local ou em uma máquina virtual do Azure, o Windows Server plataforma tem uma ferramenta nativa chamada Performance Monitor (normalmente abreviada para perfmon após o nome de seu arquivo executável) que permite monitorar métricas de desempenho de forma fácil e rotineira. Desempenho opera com contadores para os sistemas operacionais e programas instalados. Quando o SQL Server é instalado no sistema operacional, o mecanismo de banco de dados cria seu próprio grupo de contadores específicos.
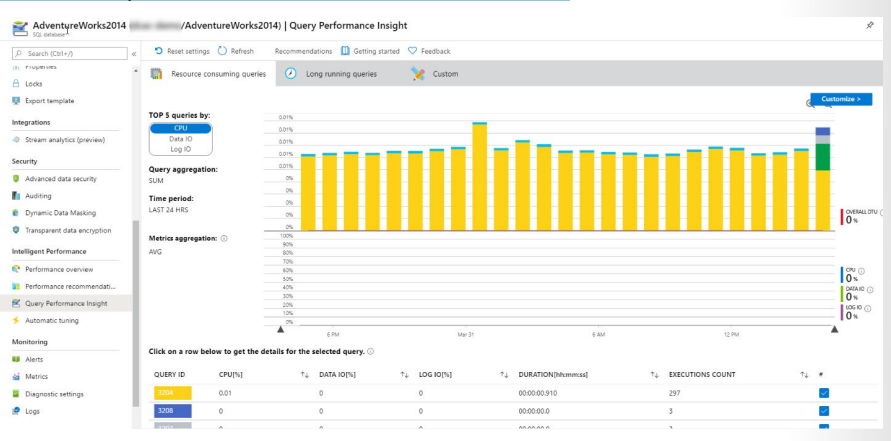
Métricas Críticas Vamos criar métricas no Azure Monitor que permitem acionar alertas ou executar respostas automáticas de erro. O serviço Azure Monitor inclui a capacidade de rastrear várias métricas sobre a integridade geral de um determinado recurso. As métricas são coletadas em intervalos regulares e são a porta de entrada para processos de alerta que irão ajudar a resolver problemas de forma rápida e eficiente. O Azure Monitor Metrics é um subsistema poderoso que permite você não apenas analisa e visualiza seus dados de desempenho, mas também aciona alertas que notificam os administradores ou ações automatizadas que podem acionar um runbook ou um webhook da Automação do Azure. Você também tem a opção de arquivar seus dados de métricas do Azure no armazenamento do Azure, pois os dados ativos são armazenados apenas para 93 dias. Criando alertas de métrica Utilizando o portal do Azure, você pode criar regras de alerta, com base em métricas definidas, na seção de visão geral de a lâmina Azure Monitor. Os Alertas do Azure Monitor podem ser definidos de três maneiras. Por exemplo, usando o Azure Máquinas virtuais como exemplo, você pode especificar o escopo como:
Uma lista de máquinas virtuais em uma região do Azure em uma assinatura (subscription)
Todas as máquinas virtuais (em uma região do Azure) em um ou mais grupos de recursos em uma assinatura (subscription) Todas as máquinas virtuais (em uma região do Azure) em uma assinatura (subscription)
Informações Inteligentes do Banco de Dados SQL do Azure (Azure SQL Database Intelligent Insights) Um dos benefícios de usar o Banco de Dados SQL do Azure é que a coleção de desempenho de linha de base criada na plataforma Azure. Além da simples coleta de dados do Azure Monitor, o Azure SQL Database Intelligent Insights é um componente do Banco de Dados SQL do Azure que permite analisar o desempenho de suas consultas. Este recurso é construído usando dados do Query Store que estão habilitados em seu Banco de Dados SQL do Azure em tempo de criação. O Query Store reúne automaticamente métricas de desempenho de consulta, incluindo tempo de execução estatísticas e histórico do plano de execução. Ele também retém esse conjunto de métricas ao longo do tempo (a duração depende da opção de armazenamento escolhida), o que permite investigar problemas de desempenho que você pode encontraram no passado.
Abordei algum dos itens do tópico pois ele é bem extenso.
Hoje vamos falar de um sub-tópico relacionado a implementação e controle de conformidade de dados sensíveis.
Dynamic Data Masking (Mascaramento de Dados Dinâmicos)
O Dynamic Data Masking permite que os usuários visualizem dados seguros sem visualizar o valor inteiro. Isso permite usuários que não precisam ver dados confidenciais, como números de cartão de crédito, números de identificação fiscal, etc. para visualizar a coluna que contém os dados, mas sem ver os dados reais que estão armazenados no mesa. É importante observar que o Dynamic Data Masking é um recurso da camada de apresentação e que os dados sem máscara sempre serão vistos pelos administradores. O melhor caso de uso do Dynamic Data Masking é dados de máscara de usuários de aplicativos que não têm acesso direto ao banco de dados. O Mascaramento de Dados Dinâmicos pode ser implementado no Portal do Azure ou usando T-SQL
ALTER TABLE Data.Membership ALTER COLUMN LastName ADD MASKED WITH (FUNCTION = ‘partial(2,”xxxx”,0)’);
No exemplo acima, o ultimo nome da tabela Data.Membership está oculto. O usuário tem permissão para ver os últimos 2 caracteres da coluna.
Implementar segurança para dados em repouso Além do T-SQL, se você estiver usando o Azure SQL Database, você pode criar regras de mascaramento dinâmico no Portal do Azure. Você pode acessar a tela de adição de regra de mascaramento navegando até seu banco de dados no Portal do Azure e selecionando Dynamic Data Masking na seção de segurança do menu principal do seu banco de dados.
O Dynamic Data Masking suporta uma variedade de padrões de mascaramento que podem ser usados. Estes incluem Padrão, Cartão de crédito, CPF, número aleatório e texto personalizado. A opção de máscara padrão mascara totalmente os dados na coluna sem expor nenhuma parte dos valores ao usuário. O usuário veria XXXX para valores de string, 0 para números e 01.01.1900 para valores de data A opção de mascaramento de cartão de crédito mascara todos, exceto os quatro caracteres finais, permitindo que os usuários visualizem o final quatro dígitos. Isso pode ser útil para agentes de atendimento ao cliente que precisam visualizar os últimos quatro dígitos de um crédito número do cartão, mas que não precisam ver o número inteiro. Os dados são mostrados no formato usual de um número do cartão de crédito XXXX-XXXX-XXXX-1234. A opção Número do Seguro Social mascara todos os caracteres, exceto os quatro últimos, com os dados mascarados exibidos como o Número do Seguro Social dos Estados Unidos no formato XXX-XX-1234.
A opção de mascaramento de número aleatório (Randon) deve ser usada em colunas numéricas. Mostra um número aleatório como o valor mascarado em vez do valor real. Cada vez que o registro é consultado, um número diferente é exibido. A opção de mascaramento de texto personalizado permite que quaisquer regras necessárias sejam especificadas. Isso permite que o texto ser mascarado com qualquer valor e exibir um número personalizado de caracteres em cada extremidade do mascarado valor. Se o valor que está sendo mascarado for igual ou menor que o número de caracteres que a máscara especifica devem ser exibidos, apenas o caractere mascarado é exibido. Um bom caso de uso do Dynamic Data Masking é exportar uma cópia de seu banco de dados de produção para um ambiente para fins de desenvolvimento, que pode ter menos restrições de segurança.
Para se aprofundar mais nesse assunto, temos a documentação oficial:
Continuando com nossa série, ainda no tópico de configuração e autenticação dos bancos no dados no Azure.
Implementar segurança para dados em trânsito
Vamos entender as práticas de proteção dos firewalls de um Azure SQL Server. O Always Encrpyted é usado para também nos ajudar a proteger os dados, em transito.
Firewalls Os firewalls são usados para impedir que usuários não autorizados acessem os recursos protegidos. Cada SQL do Azure O banco de dados é mapeado para um endereço IP público hospedado pela Microsoft. Cada região do Azure terá um ou mais endereços IP públicos onde você pode acessar seu gateway de banco de dados, que o levará ao seu base de dados. Para proteger seu banco de dados e seus dados, o Azure fornece firewalls integrados para limitar acesso. No Banco de Dados SQL do Azure, há dois conjuntos de regras de firewall, regras de firewall no nível do servidor e banco de dados regras de firewall de nível. Os firewalls no nível do servidor e do banco de dados usam regras de endereço IP em vez do SQL Server Logins. Isso permite que todos os usuários no mesmo endereço IP público acessem o SQL Server. Na maioria das empresas este será o endereço IP de saída da empresa. Os firewalls no nível do servidor são configurados para permitir que os usuários se conectem ao banco de dados mestre e a todos os bancos de dados na instância. Os firewalls de nível de banco de dados são usados para conceder ou bloquear o acesso de endereços IP específicos bancos de dados específicos.
As regras de firewall no nível do servidor podem ser configuradas usando o portal do Azure ou usando sp_set_database_firewall_ procedimento armazenado de regra de dentro do banco de dados mestre. As regras de firewall no nível do banco de dados estão configuradas por meio de T-SQL usando apenas o procedimento armazenado sp_delete_database_firewall_rule de dentro do usuário base de dados. Após a conexão, o Banco de Dados SQL do Azure procurará primeiro uma regra de firewall no nível do servidor no banco de dados master e, em seguida, uma regra de firewall no nível do banco de dados, se a cadeia de conexão especificar um nome de banco de dados. Se qualquer um deles existir, a conexão será concluída. Se nenhum deles existir e o usuário estiver se conectando por meio de SQL Server Management Studio ou Azure Data Studio, se o usuário se autenticar no banco de dados, eles ser solicitado a criar uma regra de firewall.
Pontos de extremidade de rede virtual Os pontos de extremidade de rede virtual permitem o tráfego de uma rede virtual específica do Azure. Essas regras se aplicam no nível do servidor, não apenas o nível do banco de dados. Além disso, o endpoint de serviço se aplica a apenas uma região, que é a região do endpoint subjacente. Uma preocupação adicional é que a rede virtual que é conectar-se ao Banco de Dados SQL do Azure deve ter acesso de saída ao endereço IP público do Azure Banco de Dados SQL, que pode ser configurado usando marcas de serviço para Banco de Dados SQL do Azure.
Link Privado O recurso Private Link permite que você se conecte ao Banco de Dados SQL do Azure (e outras ofertas de PaaS) usando um terminal privado. Um ponto de extremidade privado permite que uma conexão com seu banco de dados SQL do Azure seja totalmente pela rede de backbone do Azure e não pela Internet pública. Este recurso fornece um IP privado endereço na sua Rede Virtual. Outra característica do link privado é que ele permite o Azure Express Route conexões através desse circuito. O link privado oferece vários benefícios adicionais, incluindo acesso privado entre regiões conectividade e proteção contra vazamento de dados, permitindo apenas conexões a recursos específicos
Transparent Data Encryption – TDE
Por padrão, os bancos de dados em uma instância gerenciada são criptografados usando Transparent Data Encryption (TDE) com uma chave gerenciada pela Microsoft. Para fazer um backup somente de cópia iniciado pelo usuário, você deve desativar o TDE para o banco de dados específico. Se um banco de dados estiver criptografado, você pode restaurá-lo, no entanto, você precisará garantir que você tenha acesso ao certificado ou assimétrico chave que foi usada para criptografar o banco de dados. Se você não tiver nenhum desses dois itens, não será capaz de restaurar o banco de dados para uma instância gerenciada.
Criptografia de disco do Azure Além desses recursos de segurança do SQL Server, as VMs do Azure incluem uma camada adicional de segurança, o Azure Criptografia de disco — um recurso que ajuda a proteger e salvaguardar os dados e atender a organização e conformidade compromissos. Se você estiver usando TDE, seus dados serão protegidos por várias camadas de criptografia. Disco Azure Criptografia e criptografia dos arquivos de banco de dados do SQL Server e backup.
Continuando nossa série, vamos abranger o tópico “Implementar um ambiente seguro”. Vou fazendo os posts por item “master” agora porque senão não vai dar tempo de abranger tudo até a minha prova rsrs
O Banco de Dados SQL do Azure tem opções de autenticação diferentes da autenticação opções do SQL Server. Isso ocorre porque o Banco de Dados SQL do Azure e a Instância Gerenciada do SQL do Azure dependem Azure Active Directory em vez do Windows Server Active Directory.
Qual é a diferença entre Active Directory e Azure Active Directory? Uma pergunta comum é qual é a diferença entre o Azure Active Directory e o Windows Server Active Diretório, ao qual nos referiremos simplesmente como ‘Active Directory’? Isso é especialmente confuso para novos administradores porque o Azure Active Directory interage com o Active Directory. Ambas as soluções fornecem serviços de autenticação e gerenciamento de identidade, mas de maneiras diferentes – o Active Directory usa um protocolo chamado Kerberos para fornecer autenticação usando tickets e é consultado pelo Lightweight Directory Access protocolo (LDAP). O Azure Active Directory usa protocolos HTTPS como SAML e OpenID Connect para autenticação e usa OAuth para autorização. Os dois serviços têm casos de uso diferentes — por exemplo, você não pode ingressar um Windows Server em um Azure Domínio do Active Directory e trabalham juntos na maioria das organizações para fornecer um único conjunto de identidades de usuário. Um serviço chamado Azure Active Directory Connect conecta suas identidades do Active Directory com seu Azure Active Directory.
Autenticação e identidades (Authentication and identities) Tanto as instalações locais do SQL Server quanto as instalações do SQL Server nas Máquinas Virtuais do Azure oferecem suporte a dois modos de autenticação: autenticação do SQL Server e autenticação do Windows. Ao usar a autenticação do SQL Server, as informações de nome de login e senha específicas do SQL Server são armazenados no SQL Server, no banco de dados mestre ou, no caso de usuários contidos, no usuário base de dados. Usando a Autenticação do Windows, os usuários se conectam ao SQL Server usando o mesmo Active Conta de diretório que eles usam para fazer login no computador (além de acessar compartilhamentos de arquivos e aplicativos). A autenticação do Active Directory é considerada mais segura porque a autenticação do SQL Server permite para que as informações de login sejam vistas em texto simples enquanto são transmitidas pela rede. Além disso, ativo A autenticação de diretório facilita o gerenciamento da rotatividade de usuários. Se um usuário sair da empresa e você usar a autenticação do Windows, o administrador só teria que bloquear a única conta do Windows de esse usuário, em vez de identificar cada ocorrência de um login SQL. O Banco de Dados SQL do Azure também oferece suporte a dois modos diferentes de autenticação, autenticação do SQL Server e autenticação do Azure Active Directory. A autenticação do SQL Server é o mesmo método de autenticação que tem suporte no SQL Server desde que foi introduzido pela primeira vez, onde as credenciais do usuário são armazenadas dentro da master ou do banco de dados do usuário. A autenticação via Azure Active Directory permite o usuário para preencher o mesmo nome de usuário e senha que é usado para acessar outros recursos, como o Portal do Azure ou Microsoft 365.
Conforme mencionado acima, o Azure Active Directory pode ser configurado para sincronizar com o Active local Diretório. Isso permite que os usuários tenham os mesmos nomes de usuário e senhas para acessar recursos locais bem como recursos do Azure. O Azure Active Directory adiciona medidas de segurança adicionais, permitindo que o administrador para configurar facilmente a autenticação multifator (MFA). Com o MFA ativado em uma conta, depois que o nome de usuário e a senha corretos são fornecidos, um segundo nível de autenticação é necessária. Por padrão, o MFA pode ser configurado para usar o aplicativo Autenticador do Windows, que enviará uma notificação por push ao telefone. Opções adicionais para a ação MFA padrão incluem enviar ao destinatário uma mensagem de texto com um código de acesso ou solicitar que o usuário insira um código de acesso que foi gerado com o aplicativo Microsoft Authenticator.
Este login permite o acesso de administrador a todos os bancos de dados no servidor. É uma prática recomendada fazer isso conta um grupo do Azure Active Directory, portanto, o acesso não depende de um único login. A conta de administrador do Azure Active Directory concede permissões especiais e permite que a conta ou grupo que tem essa permissão tenha sysadmin como acesso ao servidor e todos os bancos de dados dentro do servidor. A conta de administrador é definida apenas usando o Azure Resource Manager e não no nível do banco de dados. Para alterar a conta ou grupo, você deve usar o Portal do Azure, PowerShell ou CLI.
Princípios de segurança (Security Principals) Entidades de segurança são entidades que podem solicitar recursos do SQL Server e às quais você pode (geralmente) conceder permissões. Existem vários conjuntos de princípios de segurança no SQL Server. Princípios de segurança existem em qualquer o nível do servidor ou o nível do banco de dados e podem ser indivíduos ou coleções. Alguns conjuntos têm um associação controlada pelos administradores do SQL Server e alguns têm uma associação fixa. Logins e funções de servidor são os princípios de segurança no nível do servidor que precisaremos estudar. Novos logins podem ser adicionados por administradores, mas novas funções de servidor não podem ser adicionadas.
Não vou entrar a nivel de logins/usuarios ou schemas pois é um ponto que é igual no ambiente onpremisse e cloud.
Então é isso 🙂 Duvidas ou sugestões só mandarem por aqui!
Vamos continuar os estudos, vou abordar todos os itens do tópico de estratégia de migração.
As soluções de infraestrutura como serviço (IaaS) do Azure são usadas com frequência ao migrar suas instalações locais ambiente para a nuvem. Existem várias ferramentas disponíveis para ajudar no processo de migração.
Ferramenta de servidor de migração para Azure Essa ferramenta de migração fornece um local centralizado para avaliar e migrar servidores locais, infraestrutura, aplicativos e dados para o Azure. Ele fornecerá capacidade de descoberta e avaliações adequadas de seus servidores independentemente de serem máquinas virtuais físicas ou VMWare/Hyper-V.
O Azure Migrate também ajudará a garantir que você selecione o tamanho apropriado da máquina virtual para que as cargas de trabalho terão recursos suficientes disponíveis. Além disso, a ferramenta fornecerá uma estimativa de custo para que você pode orçar de acordo. Para utilizar a ferramenta Azure Migrate, você deve implantar um dispositivo leve que pode ser implantado em uma máquina virtual ou física. Depois que os servidores locais forem descobertos, o dispositivo enviar continuamente metadados sobre cada servidor (juntamente com métricas de desempenho) para o Azure Migrate, que reside na nuvem.
Migrando para a Instância Gerenciada do Banco de Dados SQL do Azure A migração para instâncias gerenciadas é relativamente fácil devido ao conjunto de recursos quase completo do SQL Server. Existem algumas maneiras de executar migrações: ● Restaurando um backup ● Usando o serviço de migração de banco de dados O backup e a restauração incorrerão em mais tempo de inatividade, pois não é possível restaurar com norecovery e aplicar log backups. O serviço de migração de banco de dados é um serviço gerenciado que se conecta tanto ao seu local (ou VM do Azure) SQL Server para instância gerenciada com tempo de inatividade quase zero. Efetivamente, ele funciona como um processo automatizado de envio de log, o que significa que você pode manter seus bancos de dados de destino sincronizados, até o ponto de finalização..
Existem as ferramentas abaixo que também nos ajudam na migração de PaaS. Data Migration Assistant (Assistente de migração de dados): O kit de ferramentas MAP e o assistente de Experimentação de banco de dados podem ajudá-lo a identificar seus bancos de dados e destacar quaisquer incompatibilidades ou possíveis problemas de desempenho em seu banco de dados, mas o Data Migration Assistant (DMA) é um kit de ferramentas abrangente que avalia e identifica novos recursos que você pode usar para se beneficiar seu aplicativo e, por fim, executa a migração. Esta ferramenta pode ser usada para migrar entre versões do SQL Server, do local para uma VM do Azure ou banco de dados SQL do Azure ou SQL gerenciado do Azure Instância. Um dos principais benefícios do DMA é a capacidade de avaliar consultas de arquivos de rastreamento de eventos estendidos e consultas SQL de um aplicativo externo, por exemplo, consultas T-SQL no código do aplicativo C# para sua aplicação. Você pode gerar um relatório completo usando uma fonte C# e carregar a avaliação de migração ao DMA. O DMA reduz o risco de mudar para uma versão mais recente do SQL Server ou para o Azure SQL Base de dados.
Azure Database Migration Service: O Serviço de Migração de Banco de Dados do Azure (DMS) foi projetado para oferecer suporte a uma ampla combinação de diferentes cenários com diferentes bancos de dados de origem e destino, tanto off-line (único) quanto on-line (contínuo). sincronização de dados) cenários de migração. O DMS oferece suporte à migração de e para SQL Server para Azure SQL Banco de dados e instância gerenciada do Azure SQL. Os pares off-line de origem e destino são mostrados na Tabela 2 Origem/destinos de migração on-line para DMS. O serviço de migração de dados tem alguns pré-requisitos que são comuns em cenários de migração. Você precisa criar uma rede virtual no Azure e se seus cenários de migração envolverem recursos locais, você precisará criar uma conexão VPN ou ExpressRoute de seu escritório para o Azure. Há um número de portas de rede que são necessárias para conectividade. Uma vez que os pré-requisitos estejam no lugar, o tempo para a migração completa dependerá do volume de dados e da taxa de alteração nos bancos de dados em questão. Existem várias abordagens tradicionais e mais manuais para migrar bancos de dados para o Azure, incluindo backup e restauração, envio de log, replicação e adição de uma réplica do Grupo de Disponibilidade no Azure. Recursos que podem ser migrados offline:
Finalizando o tópico: Configurar recursos para escala e desempenho, conforme abaixo:
O SQL Server oferece suporte ao particionamento de tabelas e índices. Os dados de tabelas e índices particionados são divididos em unidades que podem ser difundidas por mais de um grupo de arquivos em um banco de dados. Os dados são particionados horizontalmente, de forma que os grupos de linhas são mapeados em partições individuais. No post abaixo tem mais informações sobre:
O particionamento pode ser feito criando no filegroup PRIMARY, em um novo filegroup ou em vários filegroups para a tabela particionada. No Azure Managed instance automaticamente são adicionados vários filegroups para o particionamento da tabela. O Azure SQL Database suporta criação de particionamento apenas no filegroup PRIMARY.
Exemplo de particionamento no filegroup PRIMARY:
CREATE PARTITION FUNCTION myRangePF1 (datetime2(0)) AS RANGE RIGHT FOR VALUES (‘2022-04-01’, ‘2022-05-01’, ‘2022-06-01’) ; GO
CREATE PARTITION SCHEME myRangePS1 AS PARTITION myRangePF1 ALL TO (‘PRIMARY’) ; GO
CREATE TABLE dbo.PartitionTable (col1 datetime2(0) PRIMARY KEY, col2 char(10)) ON myRangePS1 (col1) ; GO
A compressão é implementada no SQL Server no nível do objeto. Cada índice ou tabela pode ser compactado individualmente e você tem a opção de compactar partições dentro de uma tabela ou índice particionado. Você Explore o design de banco de dados baseado em desempenhopode avaliar quanto espaço você economizará usando o sistema sp_estimate_data_compression_savings procedimento armazenado. Antes do SQL Server 2019, este procedimento não oferecia suporte a índices columnstore ou compactação de arquivo columnstore.
Compressão de linha A compactação de linha é bastante básica e não é muito ouvida; no entanto, não oferece o mesmo quantidade de compactação (medida pela redução percentual no espaço de armazenamento necessário) nessa página compressão pode oferecer. A compactação de linha basicamente armazena cada valor em cada coluna em uma linha no quantidade mínima de espaço necessária para armazenar esse valor. Ele usa um formato de armazenamento de comprimento variável para tipos de dados numéricos como integer, float e decimal, e armazena strings de caracteres de comprimento fixo usando formato de comprimento variável.
Compressão de página A compactação de página é um superconjunto de compactação de linha, pois todas as páginas serão inicialmente compactadas em linha antes de aplicando a compactação da página. Em seguida, uma combinação de técnicas chamadas prefixo e compressão de dicionário é aplicada aos dados. A compactação de prefixo elimina dados redundantes em uma única coluna, armazenando ponteiros de volta ao cabeçalho da página. Após essa etapa, a compactação do dicionário procura por valores repetidos em uma página e os substitui por ponteiros, reduzindo ainda mais o armazenamento. Observe que quanto mais redundância em seu dados, maior será a economia de espaço ao compactar seus dados. A compressão dos dados ajuda reduzir o tamanho do banco de dados e promover perfomance de I/O em cargas altas de trabalho.
Compressão de arquivamento Columnstore Os objetos Columnstore são sempre compactados, no entanto, eles podem ser compactados ainda mais usando arquivamento compactação, que usa o algoritmo de compactação Microsoft XPRESS nos dados. Isso é melhor usado para dados que são lidos com pouca frequência, mas precisam ser retidos por motivos regulatórios ou comerciais. Enquanto esses dados é ainda mais compactado, o custo da CPU de descompactação tende a superar quaisquer ganhos de desempenho de IO redução.
Um exemplo que compressão que podemos fazer a nível de pagina:
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail ON [Sales].SalesOrderDetail with(data_compression=page)
Tudo bem? Prova chegando, por aqui suuper ansiosa rsrs
Novo item de hoje: Configurar o SQL Server em Máquinas Virtuais do Azure para escala e desempenho
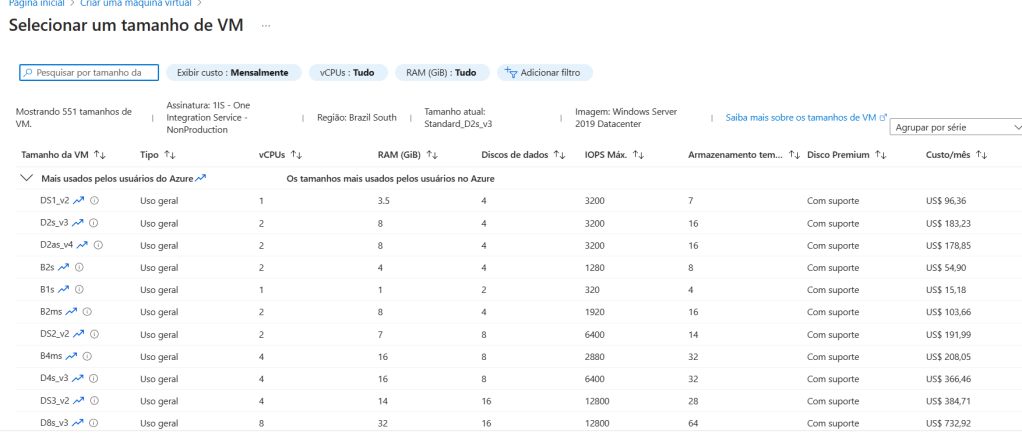
O SQL server em uma máquina Azure tem várias série de tamanhos que devem ser selecionados de acordo com a sua necessidade A seguir detalho o quadro de Tamanhos que aparece ao tentarmos criar uma VM.
Deve-se selecionar também qual a ideal configuração de hardware para sua carga de trabalho. .
Existem as seguintes series disponíveis: Uso Geral( General purpose), Computação Otimizada (Compute Otimized), Memory Memoria (Memory Optimized) , Memória otimizada(Storage optimized), etc… Não vou me aprofundar muito em cada uma delas, mas é ideal pelo menos saber as diferenças de cada uma.O link abaixo explica a diferença de cada uma. Ao criar a VM fique atenta a esses pontos:
Para validar cada opção disponível, basta alterar no Menu lateral, marcado na imagem abaixo:
A seguir um overview das mais utilizadas:
Uso geral: Os tamanhos de VM de uso geral fornecem uma proporção balanceada de CPU para memória. Ideal para testes e desenvolvimento, bancos de dados pequenos a médios e servidores web de baixo a médio tráfego. Este artigo fornece informações sobre as ofertas para computação de uso geral.
Computação Otimizada: Os tamanhos de VM otimizados para computação têm uma alta relação CPU-memória. Esses tamanhos são bons para servidores Web de tráfego médio, dispositivos de rede, processos em lote e servidores de aplicativos.
Memória otimizada: Os tamanhos de máquina virtual (VM) otimizados para armazenamento oferecem alta taxa de transferência de disco e E/S e são ideais para Big Data, bancos de dados SQL, NoSQL, data warehouse e grandes bancos de dados transacionais.
O SQL Server requer uma performance boa de Storage para entregar seus recursos com maior eficiência para aplicação.
Vamos começar mais um tópico abordado na DP-300. Os três itens abaixo eu vou abordar nesse post:
Configure Azure SQL Database and Azure SQL Managed instance for scale and perfomance.
Azure SQL Database e SQL Managed permitem você dinamicamente adicionar mais recursos ao seu banco de dados quando precisa. O escalamento dinâmico é oferecido apenas com SERVELESS (sem servidor)TIER em SQL Database.
A escalação pode ser feita direta pelo Portal do Azure, clica-se no recurso e na parte de Camada de preços (princing tier) e depoos clico em cima da parte em azul destacada abaixo:
Após abre-se uma tela nós alteramos e salvamos e o dimensionamento estará em andamento.. Nesse caso, como usamos o Nivel de computação Provisionado, o escalonamento não é feito dinamicamente.
Após algum tempo, a camada é alterada. Conforme abaixo:
Além dos passo a passo acima, temos algumas alternativas de escalação:
O recurso Read Scale-Out permite balancear o workload somente leitura do Banco de Dados SQL usando a capacidade de uma das réplicas somente leitura em vez de todas as consultas que atingem a réplica de leitura/gravação. Dessa forma, a carga de trabalho somente leitura será isolada da carga de trabalho principal de leitura/gravação e não afetará seu desempenho. É sempre habilitado no nivel de serviço Business Critical.
Databasesharding permite que você divida todos os dados em vários bancos de dados e dimensione de forma independente. Escrevi um pouco desse item no post anterior.
Entender as camadas de serviço e computação é recomendado na montagem do ambiente. Claro que não vamos decorar todos, mas saber os mais usados, assim como sua particularidades faz parre do DP-300. Existe uma documentação oficial da Microsoft que vou deixar aqui para pesquisarem: